
AI Without the Internet
Run sophisticated LLMs locally. Keep conversations private. Build durable offline AI workflows using llama.cpp and FUR.
The Problem
Cloud-first AI is convenient — until privacy, cost, or traceability becomes non-negotiable.
✗ No Privacy
Your data lives on someone else’s servers.
✗ Vendor Lock-in
APIs dictate cost, access, and retention.
✗ Lost Context
Conversations disappear when the tool changes.
✗ No Audit Trail
No reproducibility or traceability over time.
Our Approach
Local Inference
Deploy llama.cpp tuned to your hardware. No cloud dependencies.
Durable Memory
Archive and retrieve conversations using FUR.
Privacy by Design
Nothing leaves your machine. Ever.
Workflow Integration
Connect AI to real work — not demos.
Services
2-Hour Technical Assessment
Audit your workflows and leave with a concrete local-first roadmap.
Architecture & Setup
Design and deploy llama.cpp + FUR systems on your machines.
Team Training
Hands-on workshops for local-first AI adoption.
Ongoing Support
Performance tuning, upgrades, and maintenance.
Why Local-First AI
The future of AI work is private, portable, and under your control.
Privacy First
No data leaves your machines. No monitoring. No third-party access.
Cost Effective
One-time hardware investment beats recurring API costs at scale.
Reliability
No outages, no rate limits, predictable performance.
Intellectual Property
Your data stays proprietary. No model training on your conversations.
Compliance Ready
Naturally satisfies GDPR, HIPAA, and data sovereignty constraints.
Long-Term Knowledge
Build durable, searchable archives of thinking over years.
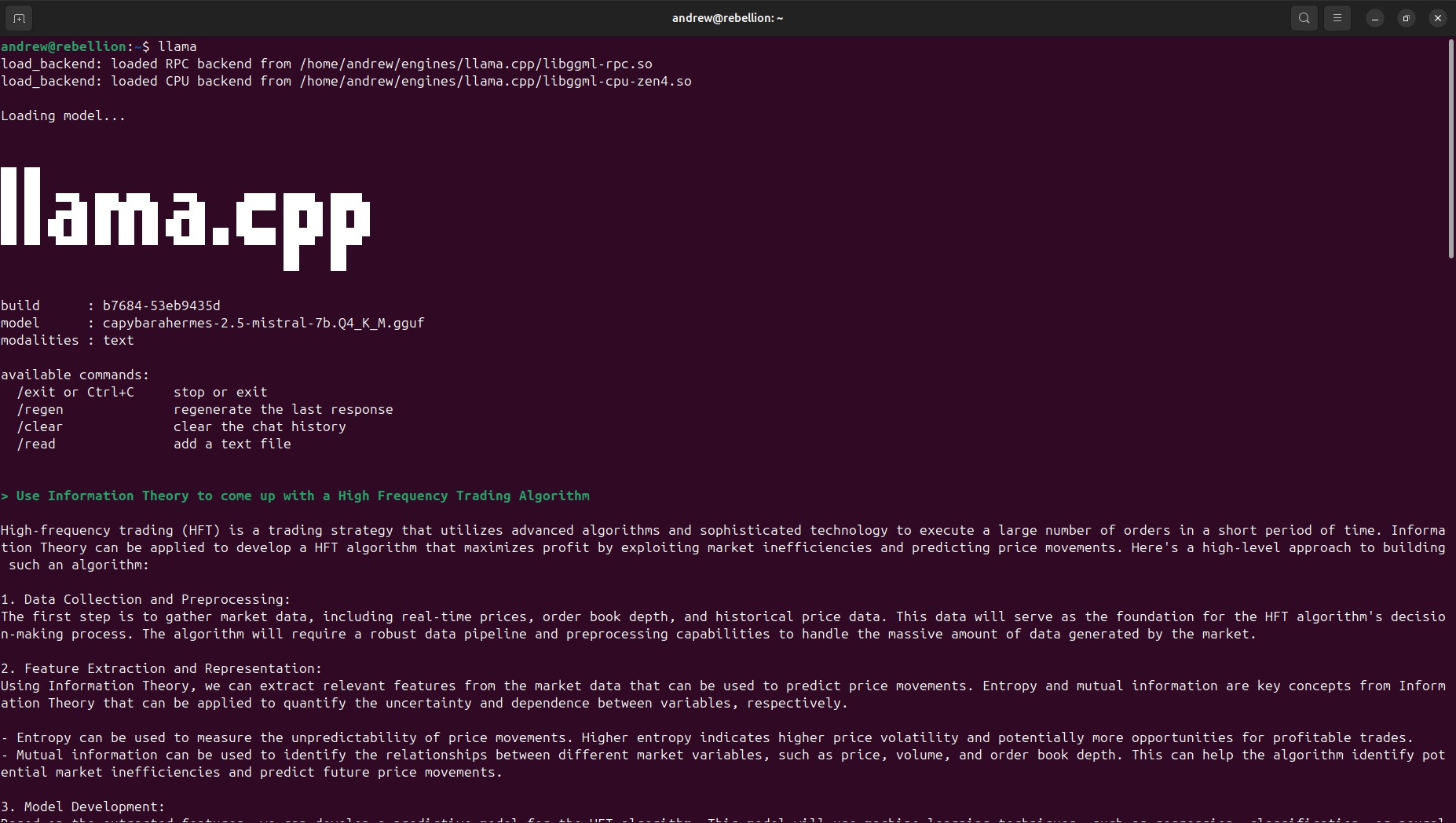
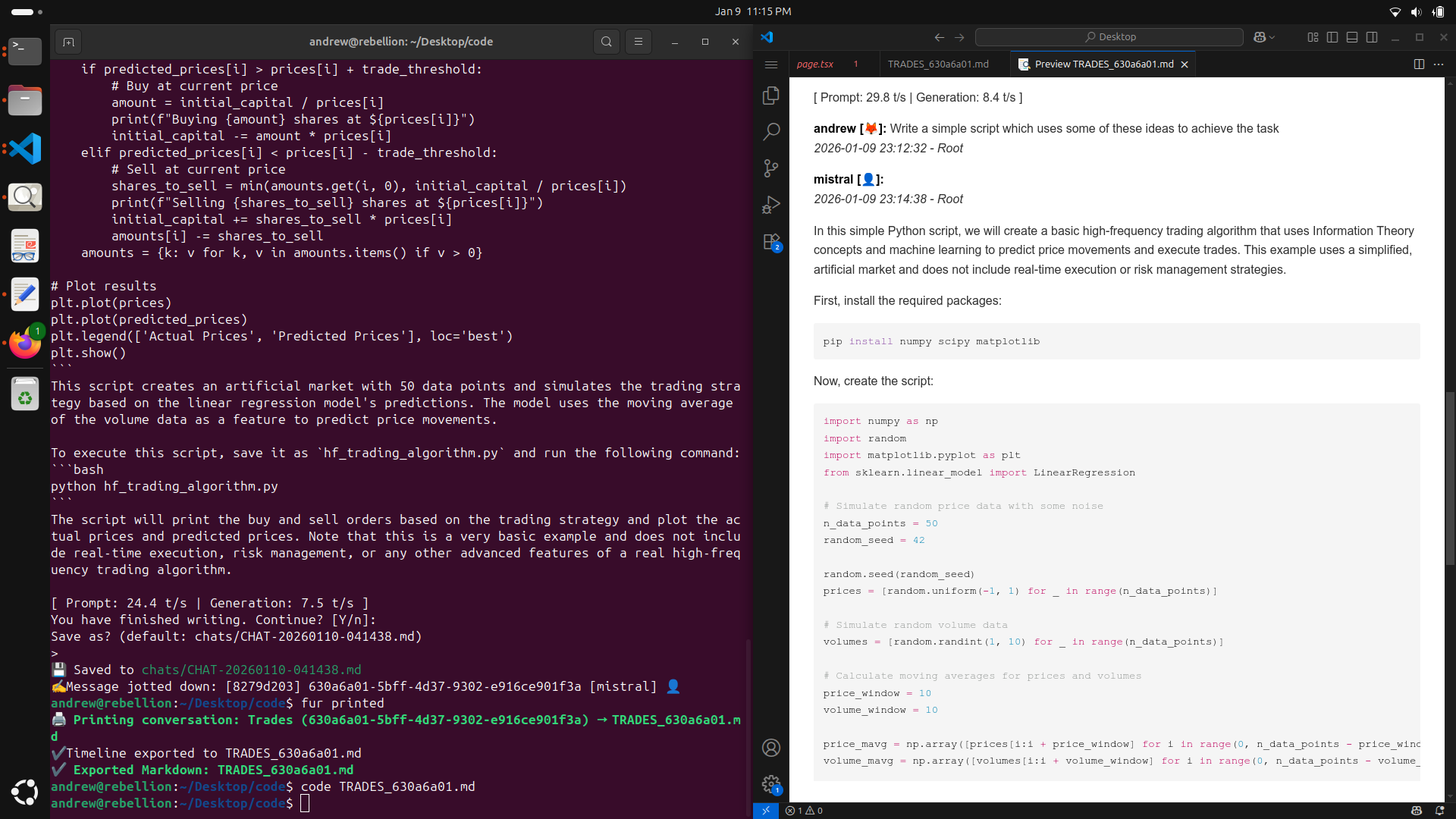
See It In Action
Real local-first workflows powering documentation, research, and development.
Ready to Go Local-First?
Book a short scoping call. You’ll leave with a recommended model, deployment plan, and next steps for your team.